- Сообщения
- 249
- Реакции
- 7
Здравствуйте.
Здоровья вам и дорогим вам людям.
Черновик с простым текстом, по разному выделены фразы, используя
Так же в тексте присутствуют строки-отточие вида
Пример:
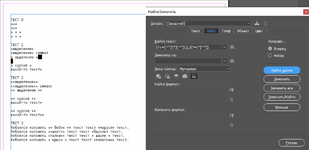
Необходимо выделить текст GREP`ом между звездочек, в разных группах
не затрагивая другую группу выделений, отточие:
1я группа-запрос
(равны)
2я группа-запрос
(равны)
3я группа-запрос-отточие (могут быть пробелы перед и после)
(равны)
Пробовал многое - не получается:
идет или захват на соседние слова/*
или только выделение "**".
Помогите пожалуйста с решением:
Выделить группы-текст между звездочками по GREP
Заранее большое спасибо!
PS
по хорошему конечно необходимо выделять еще и * после слова - вдруг где сноска
но, кажется в данном случае то приведет к сильному усложнению запросов
остается только финальная вычитка...
Не по теме:
**
прежде GREP, можно отредактировать сам текст, заменяя например ** на __
тем самым упростив задачу.
но 1: исходник-черновик может быть скорректирован и придется все заново...
но 2: в исходнике присутствуют и другие выделения, и в том случае и __
***
Пробовал:
\*{1}(.*?)\*{1}
\*{1}[^\*]+(.*?)[^\*]+\*{1}
(\*{1}[^\*]+)(.*?)([^*\]+\*{1})
(\*{1}[^\*]+)(.*?)(\*{1}[^\*]+)
(\*{1}[^\*\*]+)(.*?)(\*{1}[^\*\*]+)
(\*{1}|\*{1}\s)(.*?)(\s\*{1}|\*{1})
(?<=\*)[^\*\n] ?=\*|$)
?=\*|$)
Здоровья вам и дорогим вам людям.
Черновик с простым текстом, по разному выделены фразы, используя
*Так же в тексте присутствуют строки-отточие вида
*** или * * *Пример:
Код:
***
* * *
Побоялся изложить ** бобик ** текст текст *маруся* текст.
Побоялся изложить **шкот** текст текст *барсик* текст.
Побоялся изложить *палкан* текст текст * шарик * текст.
Побоялся изложить * крыса * текст текст *тамагочи* текст.Необходимо выделить текст GREP`ом между звездочек, в разных группах
не затрагивая другую группу выделений, отточие:
1я группа-запрос
*кот** кот *(равны)
2я группа-запрос
**кот**** кот **(равны)
3я группа-запрос-отточие (могут быть пробелы перед и после)
*** (\*{3})
* * * \*\s\*\s\*(\s+$|$)(равны)
Пробовал многое - не получается:
идет или захват на соседние слова/*
или только выделение "**".
Помогите пожалуйста с решением:
Выделить группы-текст между звездочками по GREP
Заранее большое спасибо!
PS
по хорошему конечно необходимо выделять еще и * после слова - вдруг где сноска
но, кажется в данном случае то приведет к сильному усложнению запросов
остается только финальная вычитка...
Не по теме:
**
прежде GREP, можно отредактировать сам текст, заменяя например ** на __
тем самым упростив задачу.
но 1: исходник-черновик может быть скорректирован и придется все заново...
но 2: в исходнике присутствуют и другие выделения, и в том случае и __
***
Пробовал:
\*{1}(.*?)\*{1}
\*{1}[^\*]+(.*?)[^\*]+\*{1}
(\*{1}[^\*]+)(.*?)([^*\]+\*{1})
(\*{1}[^\*]+)(.*?)(\*{1}[^\*]+)
(\*{1}[^\*\*]+)(.*?)(\*{1}[^\*\*]+)
(\*{1}|\*{1}\s)(.*?)(\s\*{1}|\*{1})
(?<=\*)[^\*\n]
?=\*|$)