- Сообщения
- 34 600
- Реакции
- 11 302
Кстати да. У ТС же, вообще CIDFont.гораздо более простую задачу решить
Ну самый примитивный случай с CID решали еще в незапамятные временаУ ТС же, вообще CIDFont.
Не-а, книги бывают 90-х годов - исходники давно утеряны, а все что осталось - пдфы с битой кодировкойИ что, нет исходника, чтобы в индизайне/кварке/неведомойзверушкевкоторойверстали подобрать шрифты которые не крякозябят в pdf и заново вывести?
В вашем конкретном примере, если нужно сохранить PDF-оригинал с исправленной кодировкой:...как исправлять в pdf-файлах кодировку текста?
А можно после перехода в "Переопределение шрифтов" поподробнее? Попробовал применить автокоррекцию - начался процесс замены кодировки (как я понял), шел минуты 3, а результате кодировка осталась прежней. Возможно, я что-то не так понял, поэтому прошу пояснить.В вашем конкретном примере, если нужно сохранить PDF-оригинал с исправленной кодировкой:
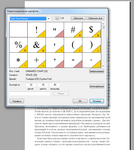
PDF > Infix PDF Editor 7.5 > Текст > Переопределение шрифтов
Acrobatist, а OCR самого акробата кстати, не устроит? Зачем в файнридер то таскать?ОСR туда не встроили
 :)")
FineReader умеет открывать pdf, предварительное ручное растрирование излишнеПеревожу файл в растровый формат (png), получается множество png-файлов...
Поиск на форуме поддерживает "*", т.е. надо было набирать "кодировк*"Я набирал "кодировк", предполагая, что при этом искомое слово найдется во всех падежах.
Если первые два пункта, которые я выполняю, проигнорировать, то при попытке запустить распознавание текста и Акробат и ФайнРидер выдадут ошибку о том, что текст итак оцифрован. Так что предварительное растрирование неизбежно.FineReader умеет открывать pdf, предварительное ручное растрирование излишне
Спасибо, буду иметь в виду.Поиск на форуме поддерживает "*", т.е. надо было набирать "кодировк*"
Лев имел в виду что правильнее все таки не превращать pdf в кучу растровых картинок и пересобирать его заново, а достаточно просто скурвить шрифты в имеющемся PDFЕсли первые два пункта, которые я выполняю, проигнорировать, то при попытке запустить распознавание текста и Акробат и ФайнРидер выдадут ошибку о том, что текст итак оцифрован. Так что предварительное растрирование неизбежно.


' '8()'")
)' '))'") Когда ты успел его заготовить?
Когда ты успел его заготовить?