- Сообщения
- 926
- Реакции
- 30
Почитал ликбез. Начал пролистивать GREP in InDesign Oreilly.
Есть известный скрипт Concordances. Того же автора, что и GREP in InDesign.
Скрипт работает за считанные секунды (когда хочет что-либо выдать).
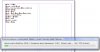
Вот искал "V P." - глаголы 5-го класса действительного
залога, за 3 секунды обработал книгу из 250 страниц.
Есть там и более интересные штуки, как-то:
Есть известный скрипт Concordances. Того же автора, что и GREP in InDesign.
Скрипт работает за считанные секунды (когда хочет что-либо выдать).
Вот искал "V P." - глаголы 5-го класса действительного
залога, за 3 секунды обработал книгу из 250 страниц.
- 40 V P. – заключать, решать,
- 42 V P. – мочь; быть
- 43 V P. – мочь; быть
- 51 V P. – скрывать, окутывать;
- 53 V P. – скрывать, окутывать;
- 58 V P. – покрывать, пересыпать,
- 58 V P. – покрывать, наполнять,
- 63 V P. – покрывать, пересыпать,
- 64 V P. – покрывать, наполнять,
- 77 V P.) – идти, двигаться
- 80 V P. – открывать, раскрывать
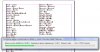
Есть там и более интересные штуки, как-то:
- claims?
- claim\w*
- 15 ; || netra n – глаз;
- 22 ; || netra n – глаз;
- 60 ); || netra n – глаз;
- 66 ); || netra n – глаз;
- netra n – глаз;
15, 22, 60, 66
- netra n – глаз;
15, 22, 60, 66 - netra n – глазик; глазунья
115, 122, 160, 166


 :)")