Всем доброго дня.
1) Сразу сообщу, что не знаю разницы между Privatedata и Metadata. По сообщениям в этой ветке создалось впечатление, что это разные понятия. Если можете разъяснить подробнее — сделайте это, пожалуйста :)")
2) Как вообще наличие Privatedata/Metadata в конечном файле PDF влияет на производительность и стабильность работы RIP, или в частности Xitron Navigator 10?
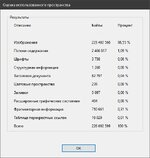
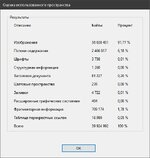
3) От верстальщика мне присылаются PDF файлы на проверку и дальнейшую отправку на CTP. Частенько файлы бо'льшего размера, чем могли бы быть. Пересохранение в Acrobat (картинка №1, выбора опций в таком сохранении нет) может кратно уменьшить размер файла (карт. №2 и №3). Есть подозрения, что дело может быть как раз в данных из п. 1. Предполагаю, что они отбрасываются при пересохранении. В этой теме у ~RA~ была попытка создать программу по удалению этих данных из EPS. Подскажите, пожалуйста, есть ли какое-то решение, чтобы по принципу горячей папки файлы PDF автоматически обрабатывались на предмет удаления этих данных?
1) Сразу сообщу, что не знаю разницы между Privatedata и Metadata. По сообщениям в этой ветке создалось впечатление, что это разные понятия. Если можете разъяснить подробнее — сделайте это, пожалуйста
2) Как вообще наличие Privatedata/Metadata в конечном файле PDF влияет на производительность и стабильность работы RIP, или в частности Xitron Navigator 10?
3) От верстальщика мне присылаются PDF файлы на проверку и дальнейшую отправку на CTP. Частенько файлы бо'льшего размера, чем могли бы быть. Пересохранение в Acrobat (картинка №1, выбора опций в таком сохранении нет) может кратно уменьшить размер файла (карт. №2 и №3). Есть подозрения, что дело может быть как раз в данных из п. 1. Предполагаю, что они отбрасываются при пересохранении. В этой теме у ~RA~ была попытка создать программу по удалению этих данных из EPS. Подскажите, пожалуйста, есть ли какое-то решение, чтобы по принципу горячей папки файлы PDF автоматически обрабатывались на предмет удаления этих данных?